
MySQL增删改查(进阶)
ok,上篇文章分享了表的设计一些相关内容,那么接下来分享下MySQL中的增删改查相关进阶操作吧。
查询和新增
此操作将查询到一个表的数据插入到要插入表中。
比如,我现在创建两个表:

并且往stu1插入一下数据

接下来往stu2插入数据
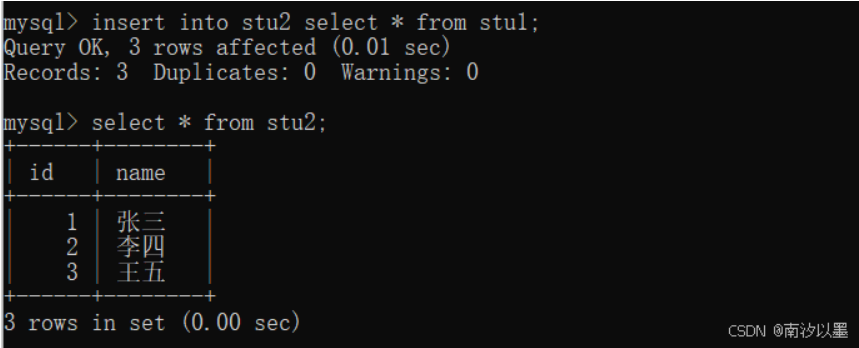
值得注意的是,这种查询和插入结合起来的时候,要保证这两个表的结构要相同的,
以及,插入的时候,values这时候是可以省略的。
下一个介绍聚合查询
聚合查询
这个查询操作是来针对行于行之间的查询的。
聚合操作一般搭配聚合函数来查询。
MySQL提供了以下的一些聚合函数
而其中的distinct和expr是分别代表,查询的时候可以去重,以及查询可以是一个表达式或者是列。
下面来分别介绍一下吧
count
表就用以下这个表
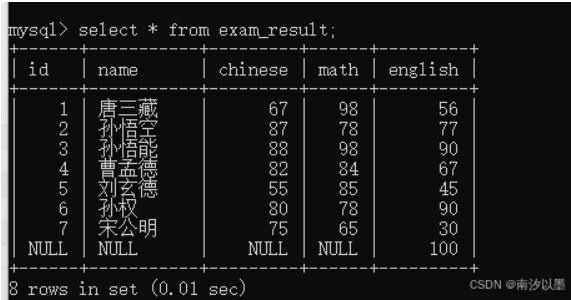
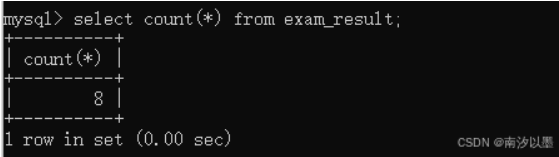
这里的执行顺序是,先是from,再到count函数,再到select。
但如果针对某列的时候,空值是不计入计算范围的
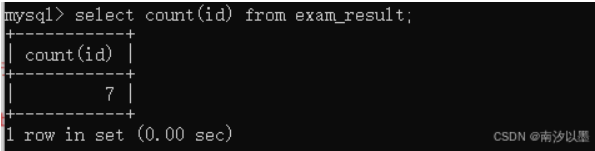
值得注意的是,count ()之间不能有空格,否则会报错

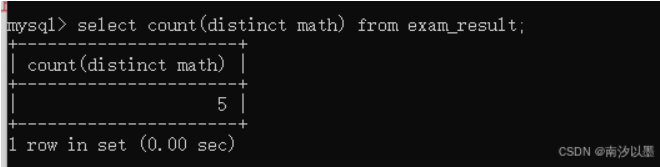
此外,count函数还可以对某列进行去重
sum
sum函数可以进行对某一列进行求和
还是以这个表为例子:
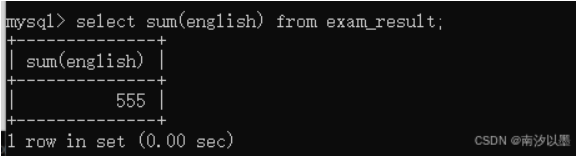
比如针对English这列进行求和
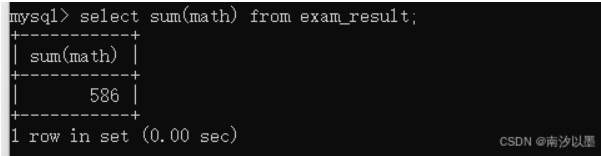
即使是这列中有null值也是可以正常计算的
值得注意的是,并不可以对字符串那一列进行求值
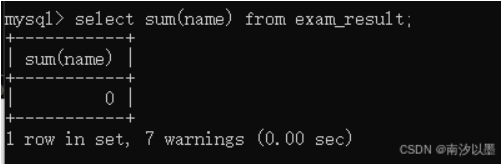
并且还会报出警告
查看警告: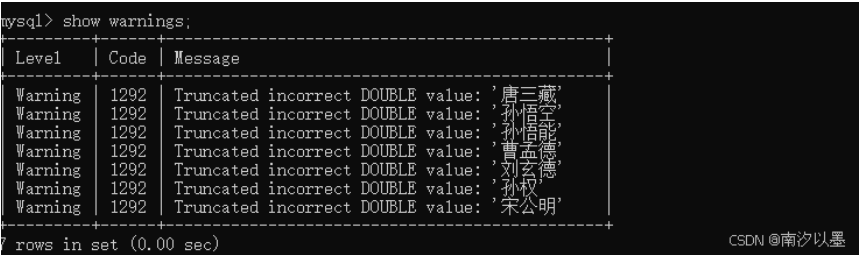
告诉我们如何前半部分字符串中包含数字,将会截断并转换为double出来。
同时,我们也要注意到是,不应该对某些很长的数据进行求和,比如学号、身份证号……
avg
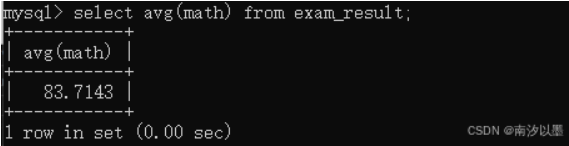
还是以这个表为例子:
这个是对某列进行平均求值
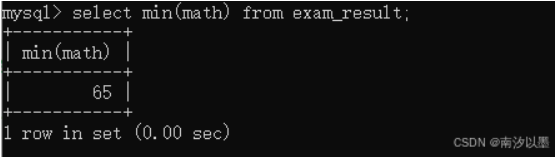
min/max
还是以这个表为例子:
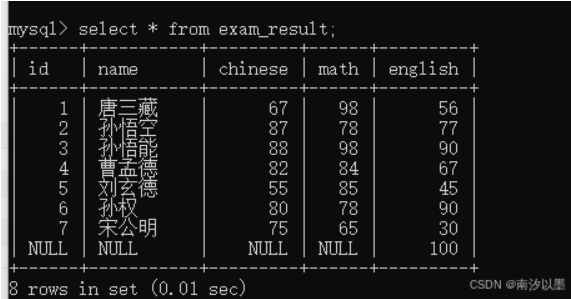
这个是对某列中求出最小值/最大值
聚合查询中还有一个重要的操作——group by
分组查询
分组查询是会把的值相同的行,归到一组中
分完组之后,还可以针对每个组,分别进行聚合查询。
首先来个简单且较为直接点的
比如使用以下这个表
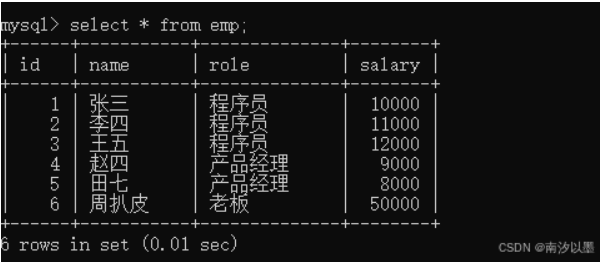
简单直接分组查询后的结果
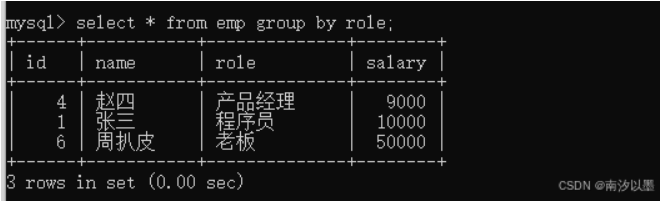
值得注意的是,建议以后进行分组查询要在select 后加入相关的列,避免以后数据量大了后
查询更多干扰信息,还有,salary这一列的数值排列,我们没有指定,所以该行为是不确定的。
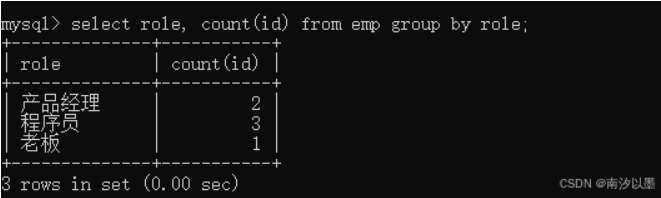
这里我们使用group by 和count
这就类似于role中的去重,并显示各个职位的人数。
另外我们也可以对平均薪资进行分组
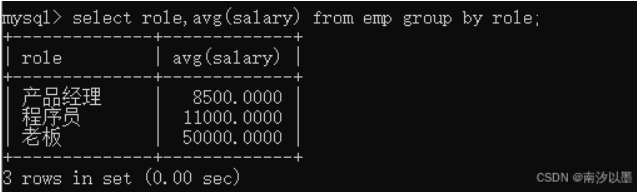
这个执行流程是先从emp读取数据,如何group by进行分组,然后进行avg计算,最后在显现给用户。
值得注意的是,若我们没有指定任何排序方法,图中的排序是不能确定的。
当然也可以分组完进行排序
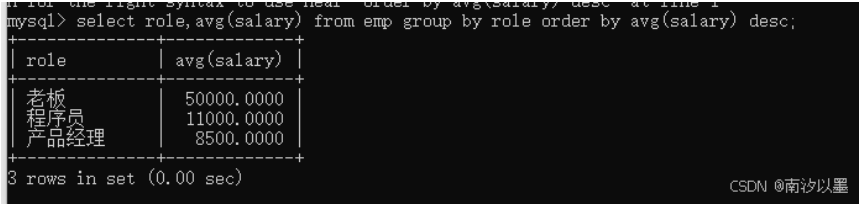
此外,我们还可以搭配条件进行使用
分组之前查询

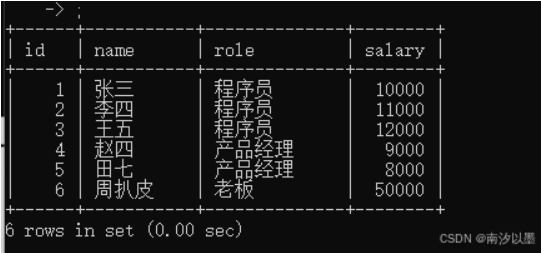
查询平均薪资,但是去除张三。
分组之后查询
查询,每个岗位的平均薪资,排序平均薪资超过50000的

当然,可不可以分组之后,分组之前都用上呢?
其实是可以的

这个意思是,查询每个岗位的平均薪资,但去除了小于50000的以及name=张三的。
接下来介绍一种较为复杂查询
联合查询(多表查询)
引入之前,得介绍一个较为重要的东西,叫做笛卡尔积
这个笛卡尔积简单来说就是排列组合
把两个表里的数据,按照一定的规律,进行排列组合
举以下的例子:
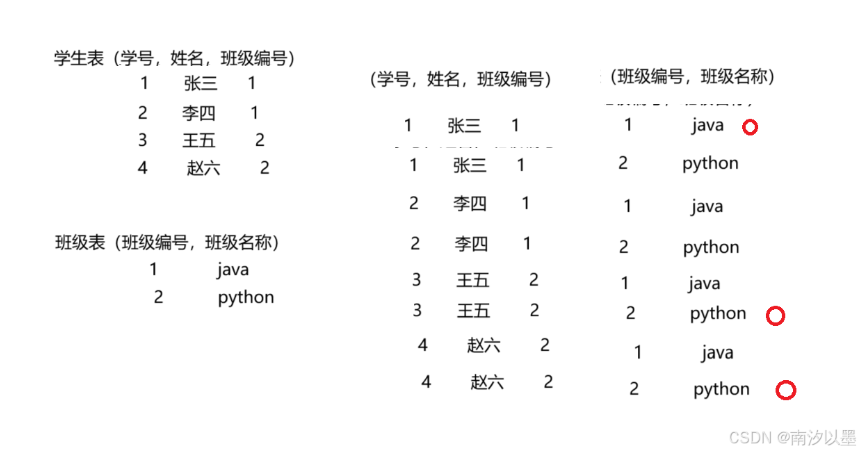
对班级表和学生表进行一一的排列组合,就得到了这个
其中打圈的是符合我们内容的。
其他一些无意义的数据,需要我们通过条件进行筛选掉。
那么如何通过sql计算笛卡尔积呢?
比如这两张表来说

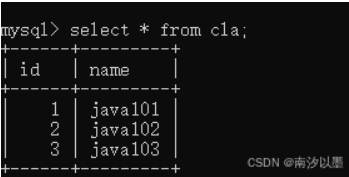
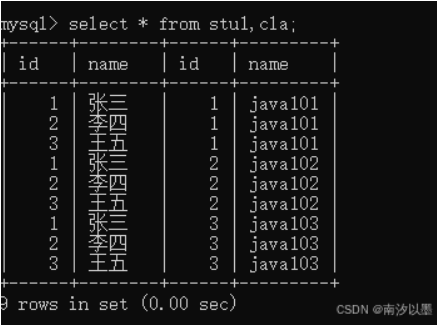
以上就是如何直接的的笛卡尔积了。
而如何进行一些,有意义的操作呢?
比如,查询出,cla和stu1表相同id的情况
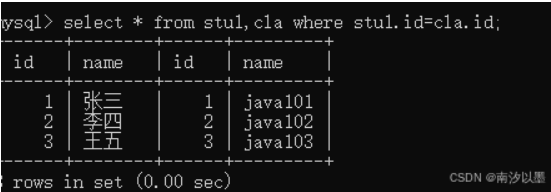
这里是一样的情况,是因为,我插入都是一一对应的数据。
ok,那么多表查询,我们执行的流程一般是什么呢?
1.笛卡尔积(明确对象来自己于哪几个表,对这几个表进行笛卡尔积)
2.指定连接条件,将一些无意义的数据进行干掉。
3.进一步添加筛选条件
4.把查询的列进行精简。
ok,下面举个例子进行运用以下。
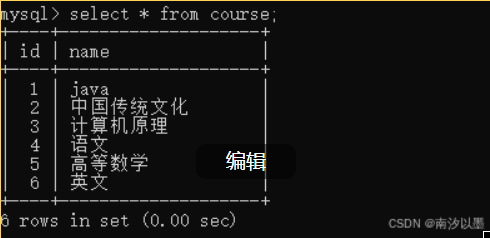
比如,我们有以下这几个表
班级表:

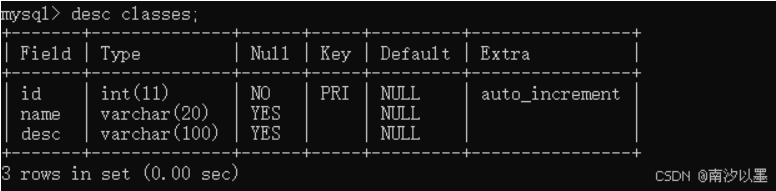
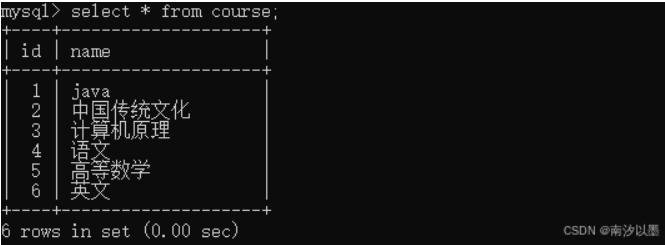
课程表:
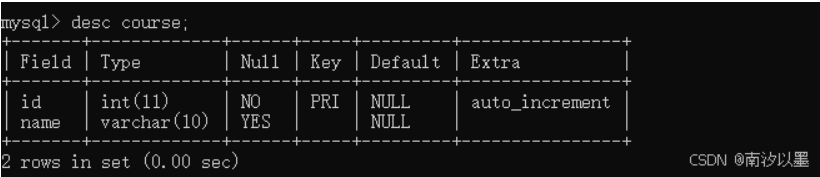
分数表:
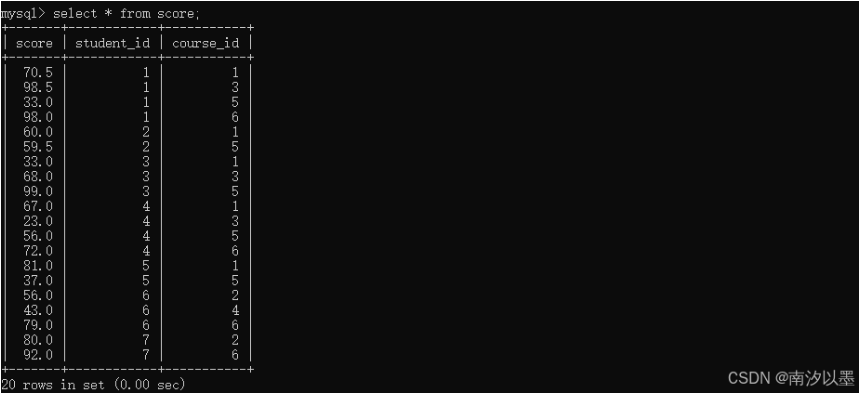

学生表
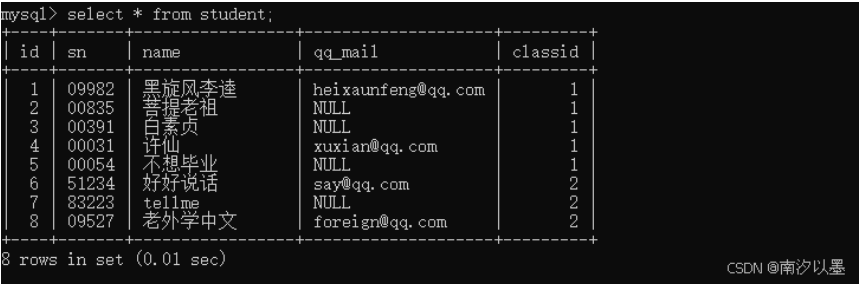
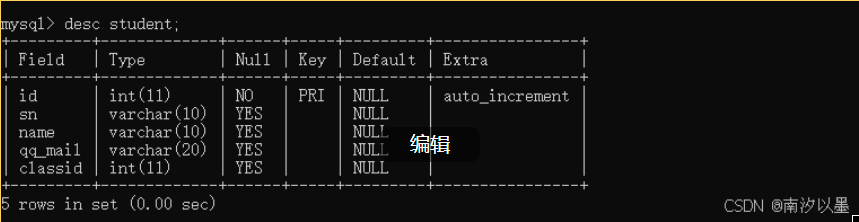
比如
现在查询白素贞的成绩。
既然是成绩和名字,那么涉及到两个表
学生表、成绩表
对这两个表进行笛卡尔积
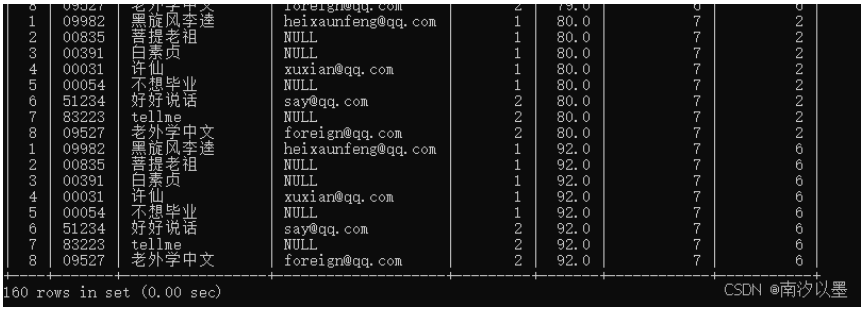
查询到160条数据,就截图了一部分。
接下来进行一些条件连接,把无意义的数据干掉!
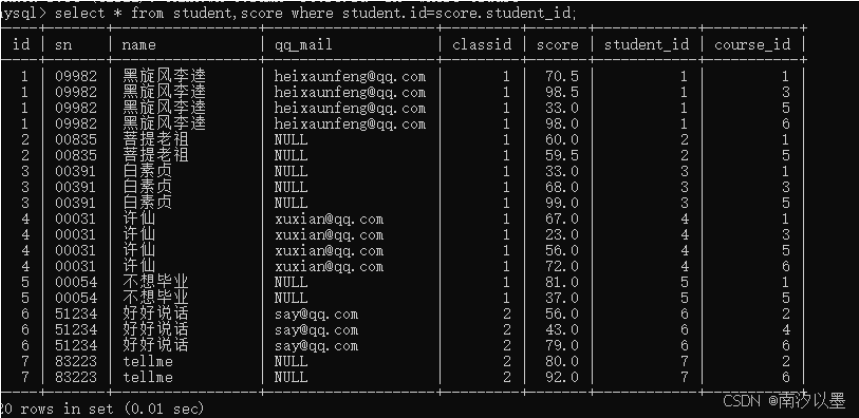
然后根据需要,再对内容进行进一步的筛选。

然后,发现列太多了,所以我们对列进行一些精简

当然,我们除了,这个where写法,我们还有join on 写法,同样举个上面的例子
1.确定那些表
学生表和分数表

这里同样会查出160条数据的
2.指定连接条件,筛选掉无意义的数据
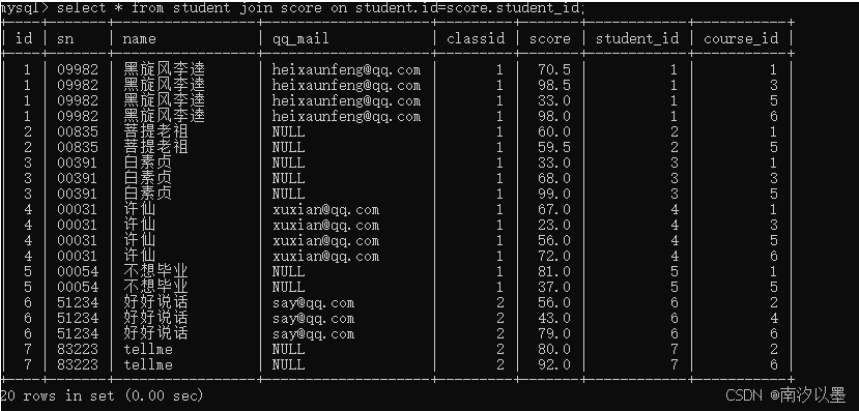
3.根据需要再对一些数据进行筛选

4.然后进行对列的精简(当然这里也是根据需要来的)

上诉操作只是拿个简单表来进行举例,以后要进行笛卡尔积的时候,要合理预估,笛卡尔积后的数量有多大,再进行合适的操作。
ok,讲完这个
那么接下来讲讲,什么是内连接和外连接吧
内连接
我们刚刚上诉的操作也是涉及到,但是为了简单明了的,还是举个以前例子
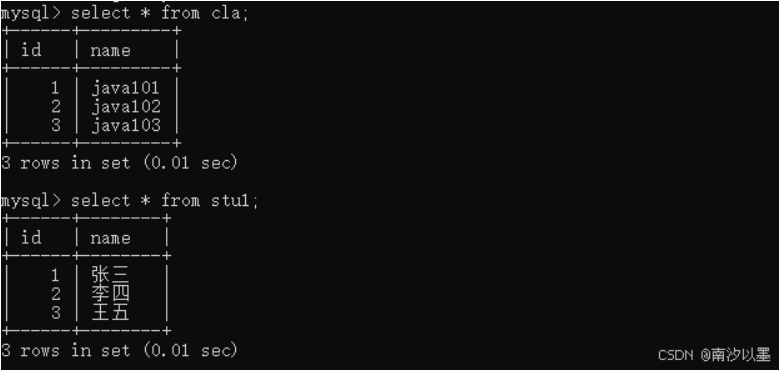
这是我们创建好的两张表
可以看到,其中id这一列,是一一对应的,
所以这是内连接一一对应的。
当然,如何是下面的情况
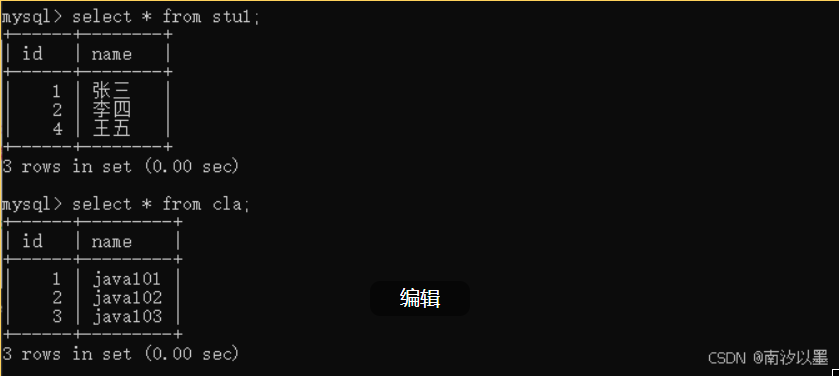
这就不是一一对应了,这是外连接了。
这种情况下,去表达内连接的时候,可以这样子
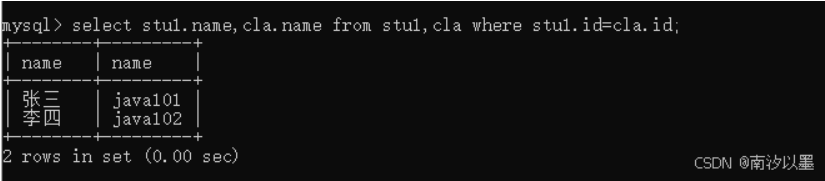
也可以用join on
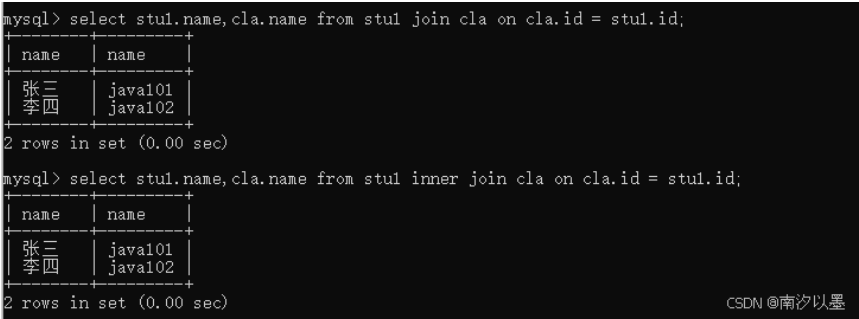
这里我们加个inner会显得的更为显示说明是内连接。
但值得注意的是where只能表示内连接,不能表示外连接。
外连接
外连接也分左外连接和右外连接
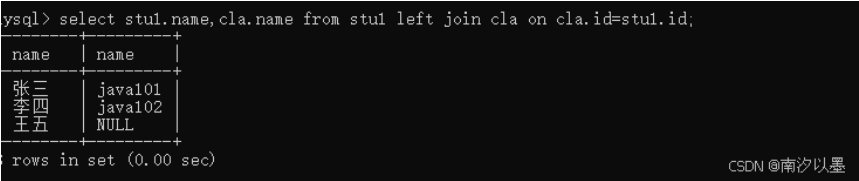
这是左外连接的写法
左外连接以左表(这里写的是stu1)为基准,确保左表每个数据都在最终结果里,如若左表的记录
右表没有的话,那么此时会把右表的相关字段变为NULL;
同样的右连接也是如此
只不过把右表位置基准,左表改为右表

当然,我们这里还会有一个特别的情况
那就是自连接
自连接
顾名思义就是自己和自己进行笛卡尔积
场景使用,比如,一个表中两行数据进行比较
但是数据库中,是列与列进行比较的
所以,这个自连接是可以将行与行的比较转换成列于列的比较
这里举个之前笛卡尔积的例子
比如我们查询计算机原理比java高的成绩信息
但值得注意到是,我们不能直接进行笛卡尔积

这是说,我们的表名不是唯一的
所以,我们另起别名
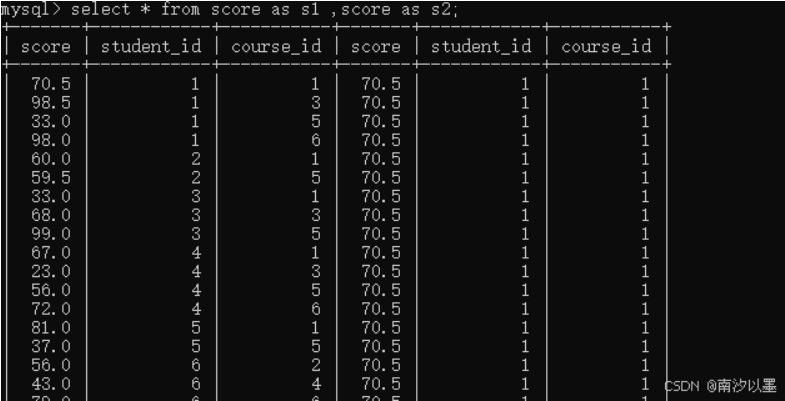
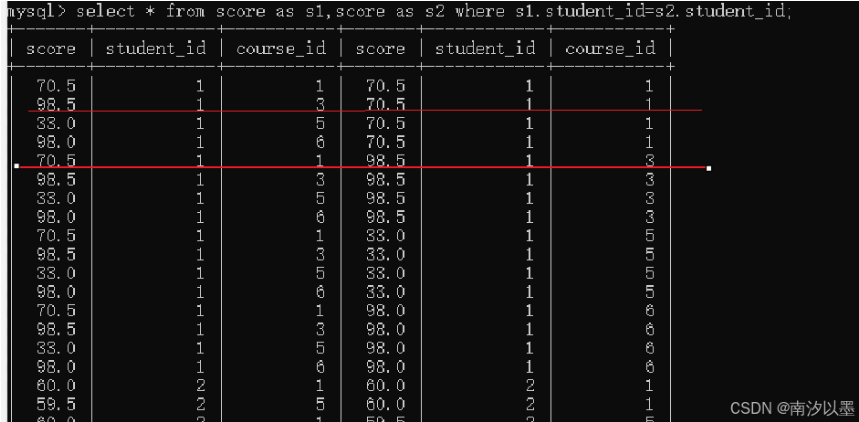
这里我们会有四百条数据查询出来。
ok,然后,按照之前的操作
指定连接条件,筛选无意义的数据
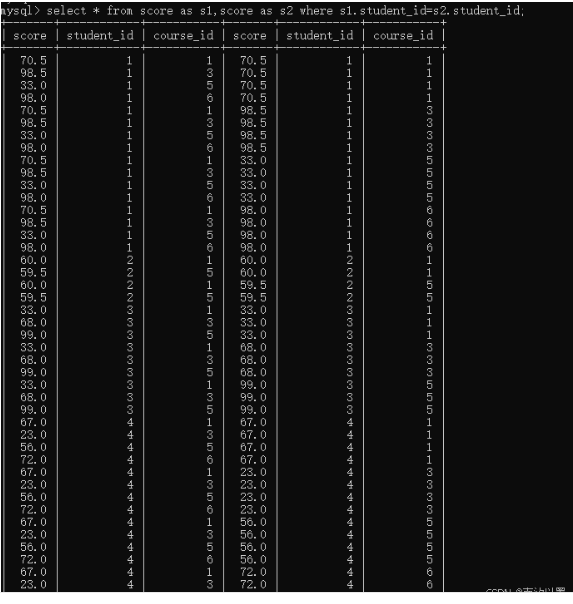
同时我们细心观察发现这两列数据
这里按照学生id作为连接条件的时候,此时分数和课程就相当于进行排列组合。
当学生id相同时,其课程id表示为1、3,从以前的两行比较
到现在的,行相同,变成列比较了。
接下来进行下一步操作,

这里筛选出,courseid=3和1的出来
而且是计算机原理比java成绩高的,所以,这里说把3放在前面。
最后,进行对列的精简

自连接讲完,那么来讲讲这个子查询吧
子查询
通俗点就是套娃。
意思就是说一个需求,多个sql语句结合,才是合理的,然后非得放到一个sql中查询
举个例子:
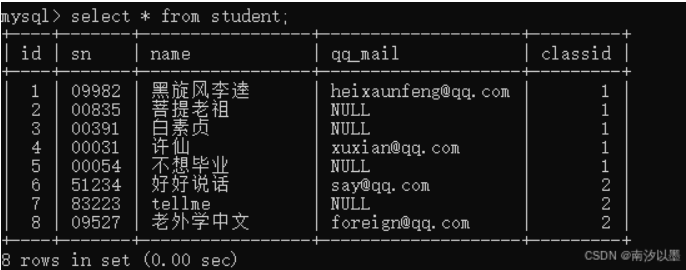
以上面的表为例,查询老外学中文的同班同学。
正常的来说
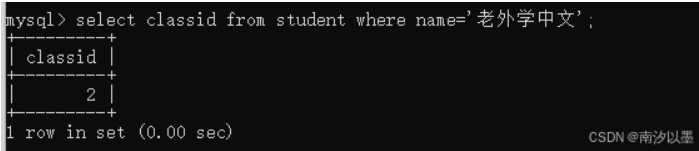

当我们放到同一个sql中,结合起来,就成了子查询

这个是单行的
还有多行子查询
多行子查询
比如
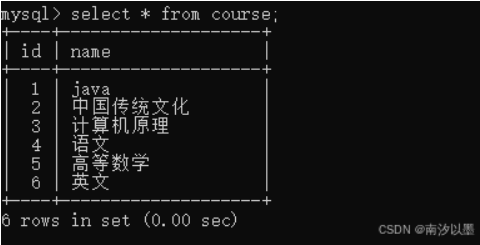
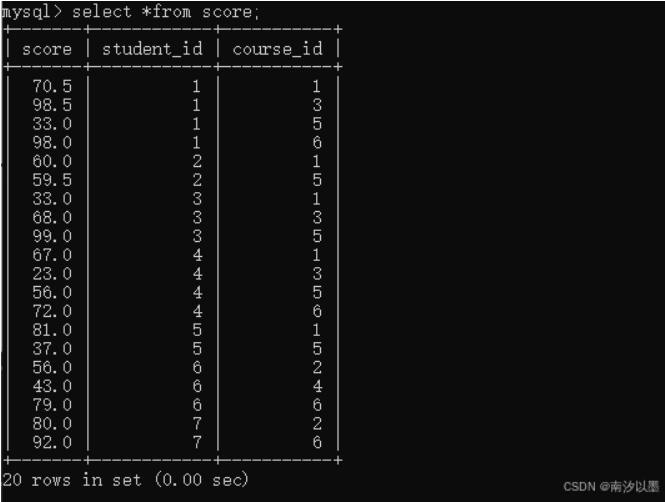
拿这两个表举个例子
查询语文和英文的成绩
首先,我们呢
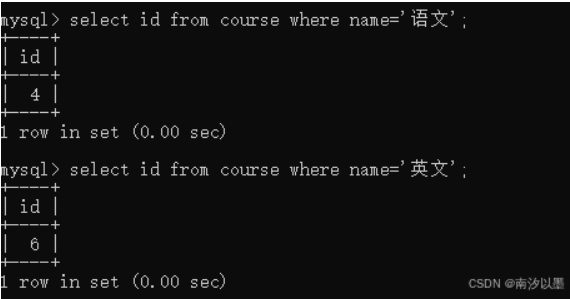
先查询这个
然后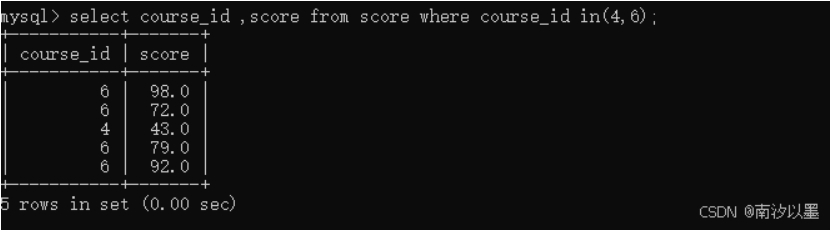
当我们放入同一个sql的时候

所以,这样的可读性差,简单合为一起变得复杂,不推荐使用。
然后,最后介绍一个是合并查询。
合并查询
把多个select的结果显现出来
举个例子
比如
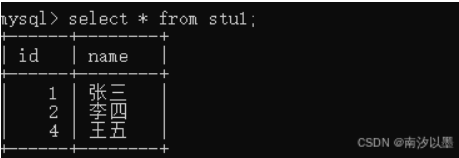
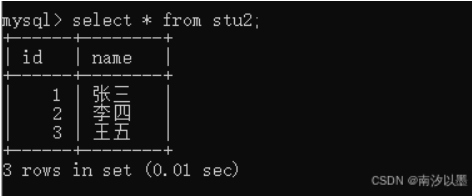
以这两个表为例子

这个union比on使用范围广一些,
刚刚上面的操作可以用on实现
但是union还可以对两个表进行展现,刚刚是一个表的。
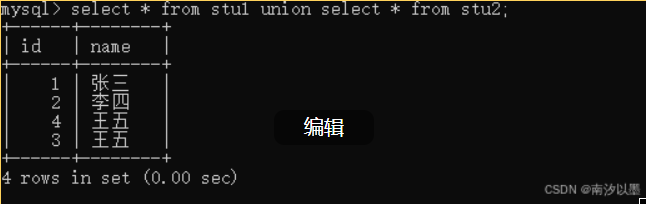
当然,你会发现,这里显现不全的。
因为我们发现是有重复的话,是要去掉的,包括是id和name
如若我们要显现全部出来
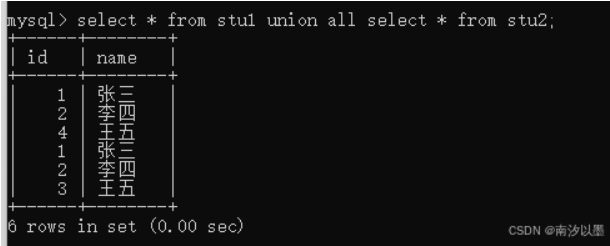
但值得注意的是,
合并查询的时候,两个表的类型、个数、顺序、匹配相同
列名不做要求。
到这里,进阶分享完!
&pics=/upload/Snipaste_2025-08-12_10-49-56.png&summary=){kind=link}
&pics=/upload/Snipaste_2025-08-12_10-49-56.png&desc=){kind=link}